More Complex Geospatial Methods
This section includes information on more complex geospatial methods such as parametric regression, splines and kernel smoothing, nonparametric regression and multiple regression. These methods offer some potential advantages over the simple methods because they allow predictions from the data and estimate the uncertainty of those predictions. The assumptions, strengths, and weaknesses of each method are described, as well as guidance on using the method results. An example at the end of this section illustrates how the results of these geospatial methods can be applied to address specific optimization questions.
These methods can predict values for the variable of interest based on functions of the coordinates, but they work best when additional explanatory variables are available. Explanatory variables can include almost any type of information that is related to the quantity of interest, even data that are categorical (for example, soil type).
Methods based on splines and kernel smoothing are extremely flexible and can be used to accommodate physically important features in mapping such as break lines and barriers. Spline methods can produce maps that account for autocorrelation in a way that is equivalent to kriging (Wahba 1990). The main difference between splines and kriging is how the degree of smoothing is estimated and how uncertainty estimates are provided. Nonparametric regression uses spline and kernel smoothing methods within a regression framework.
Multiple regression allows the examination of the relationship between multiple variables associated with each point or unit of observation (concentration, soil type). Any variable can be a function of any other variable measured on the same sample. Multiple regression is a useful tool with which to examine relationship among the variables and to predict the value of one variable based on the known values of the other variables. The regression example illustrates various regression approaches.
Parametric Regression
Global parametric linear regression (which includes all the relevant data from the site) fits a simple polynomial function of the data coordinates and possibly other explanatory variables. This approach is often called “trend surface analysis” when fitting low-order polynomial functions of the coordinate variables. The surface generated by the polynomial changes gradually and captures the large-scale (global) pattern in the data. Trend surface analysis on its own may be too simple to create useful maps in most cases, but when it is combined with kriging it is a powerful method. The methods available for combination include universal kriging, kriging with an external trend, and regression-kriging.
There are many available modifications to the traditional linear regression method that extend its flexibility and usefulness. In particular, generalized linear models (GLMs) allow the modeling of non-normal distributions and accommodate a degree of non-linearity in the model structure. These methods are not described in this guidance. An introduction to these methods is provided by Dobson (2001), and the comprehensive reference is McCullagh and Nelder (1989).
Assumptions
Strengths and Weaknesses
Understanding the Results
Splines and Kernel Smoothing
Spline and kernel smoothing methods represent a wide class of smoothing interpolation methods. One method of interpolation is to fit a polynomial surface the measured data points, where a global polynomial encompasses the entire area of interest, but may not contain sufficient detail to capture small scale variations. Local polynomials can be used to capture small scale variation, but they may not apply universally. A piecewise polynomial fitting combines adjacent local polynomial models into a patchwork model; the models can be generated using different polynomial functions but their boundaries must line up for an even joining.
Aligning boundaries is accomplished through the use of splines, which describe how the joined model behaves at the boundary between the different polynomial functions. Splines allow a smooth transition and a flexible interpolation surface. A spline is a special type of piecewise polynomial, in which the smoothness of the interpolation is controlled by a smoothing parameter. There are many different types of spline that behave similarly, including smoothing splines, regression splines, and penalized splines. The smoothing factor controls the tradeoff between fitting the data exactly and the degree of smoothness in the interpolation.
In contrast to spline smoothing, kernel smoothing is a type of moving average interpolation, in which the kernel function provides the weight that each data point receives in the average. The degree of smoothing depends on the choice of kernel function and kernel radius. Increasing the kernel radius results in a smoother interpolation as the moving average is performed over a larger area. Kernel smoothing is also called local regression.
Splines and kernel smoothers are simple to use and are readily available in many software packages. Unlike advanced spatial interpolation methods, such as kriging (Section 8.3), splines and kernel smoothers do not require estimation of a statistical model of spatial correlation. For mapping as part of exploratory spatial data analysis, all that is needed is a list of locations and values, as well as a smoothing factor or kernel function and radius. A smoothing factor of zero will produce an interpolation spline that exactly interpolates the data. Larger smoothing factor values will smooth the spline to a greater degree. Similarly, the kernel radius controls the smoothness of the kernel smoother. These smoothing parameters can be chosen manually based on a visual appraisal of the resulting maps or through cross-validation.
Typical Applications
Strengths and Weaknesses
Understanding the Results
Nonparametric Regression
Nonparametric linear regression, also called local spatial regression, is a class of methods that use more flexible approaches for modeling than simple global polynomials. The model structure is similar to linear regression, but it involves a sum of smooth functions of the covariates. The smooth functions can be constructed from a wide variety of basis functions, including splines and kernel smoothing methods. Spline methods are based on piecewise polynomial fitting, while kernel or local regression methods are based on local polynomial fitting. All methods have parameters that control how smooth they are, with the value of the smoothness parameter selected by iterative cross-validation.
Assumptions
Strengths and Weaknesses
Understanding the Results
Regression Example
In the following example, a data set consisting of 155 samples of topsoil collected from the flood plain of the River Meuse (located in the Netherlands) was analyzed. The samples were analyzed for heavy metals, but the focus of this example is on interpolating zinc concentrations. Several of the methods presented in the EDA section and the parametric and nonparametric regression sections are used in this example to illustrate the progression of analysis.
Spatial regression is appropriate here because several predictor variables are available. Figure 61 is a plot of the zinc concentrations in parts per million (ppm), with the River Meuse shown in blue. The R Statistical Software was used in this example, and the example data are provided with the sp R package (Pebesma and Bivand 2005).
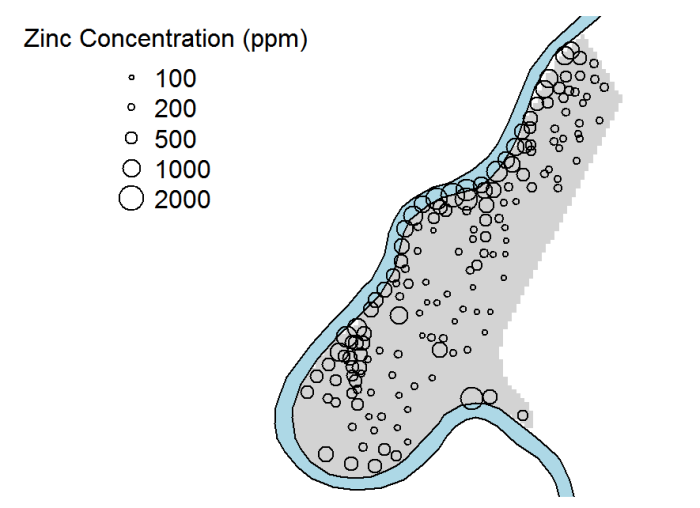
Figure 61. Plot of zinc concentrations in soil near River Meuse, The Netherlands.
Exploratory Data Analysis – River Meuse
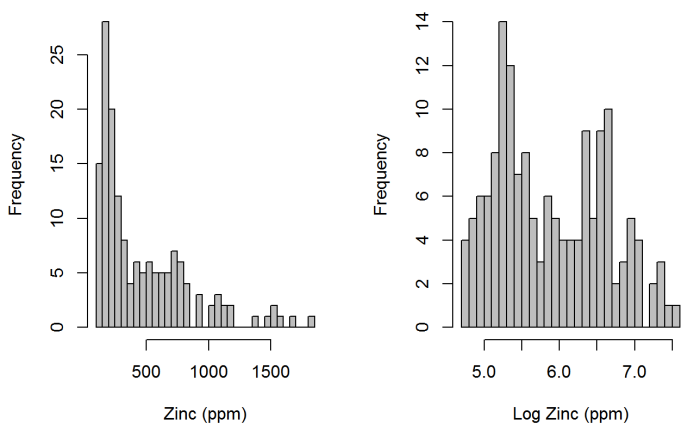
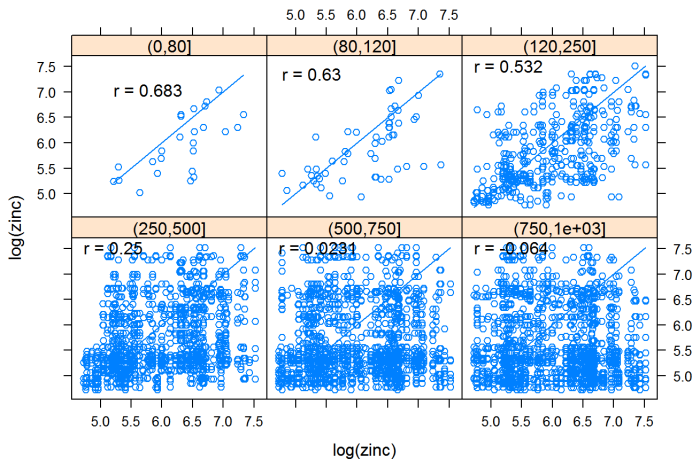
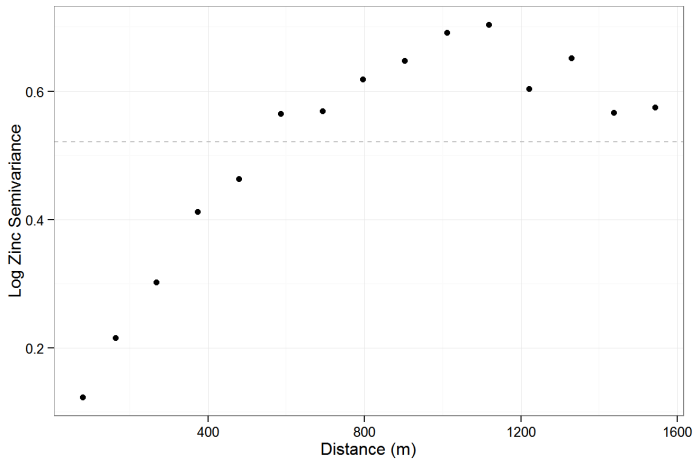
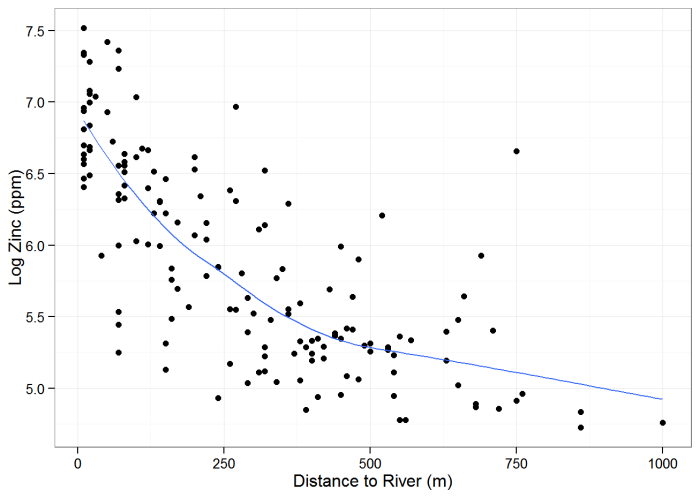
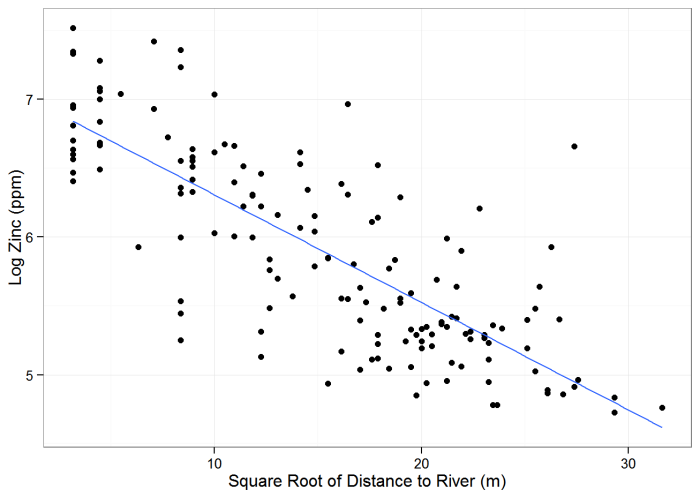
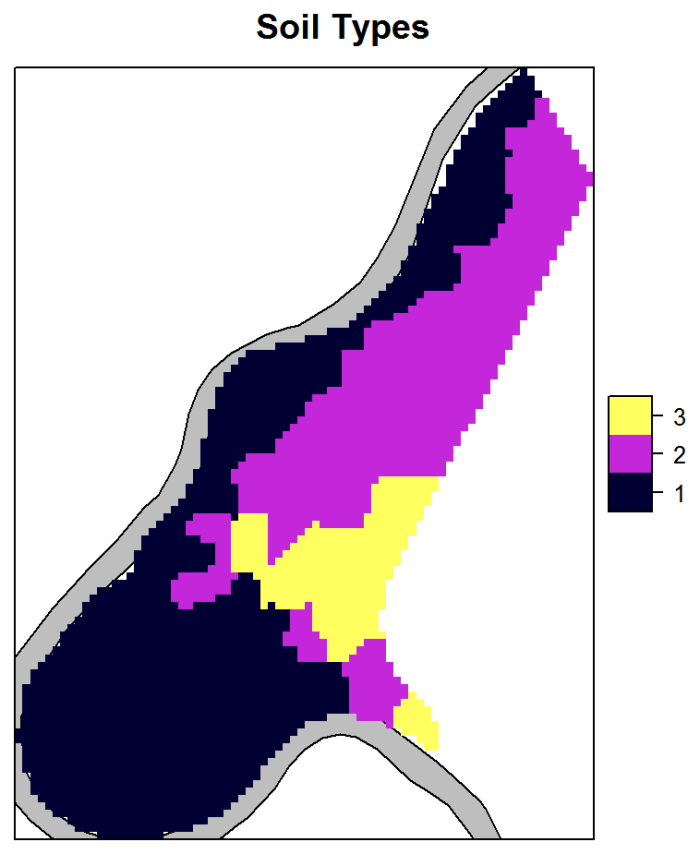
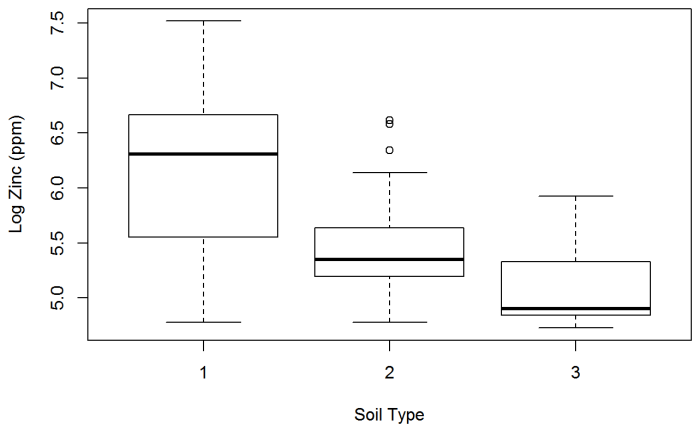
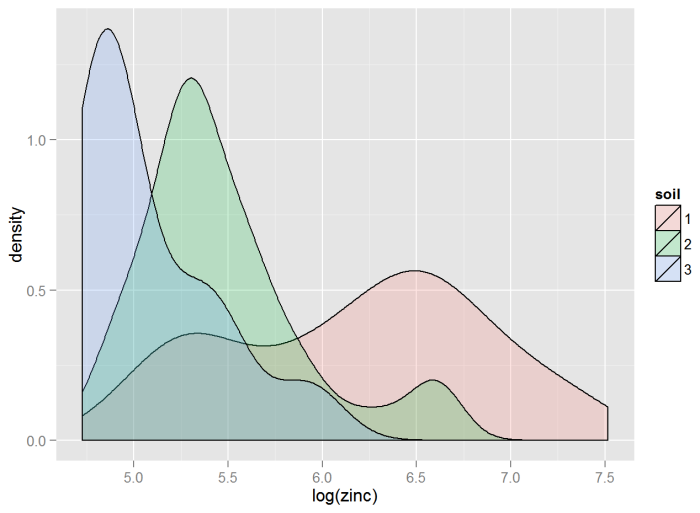
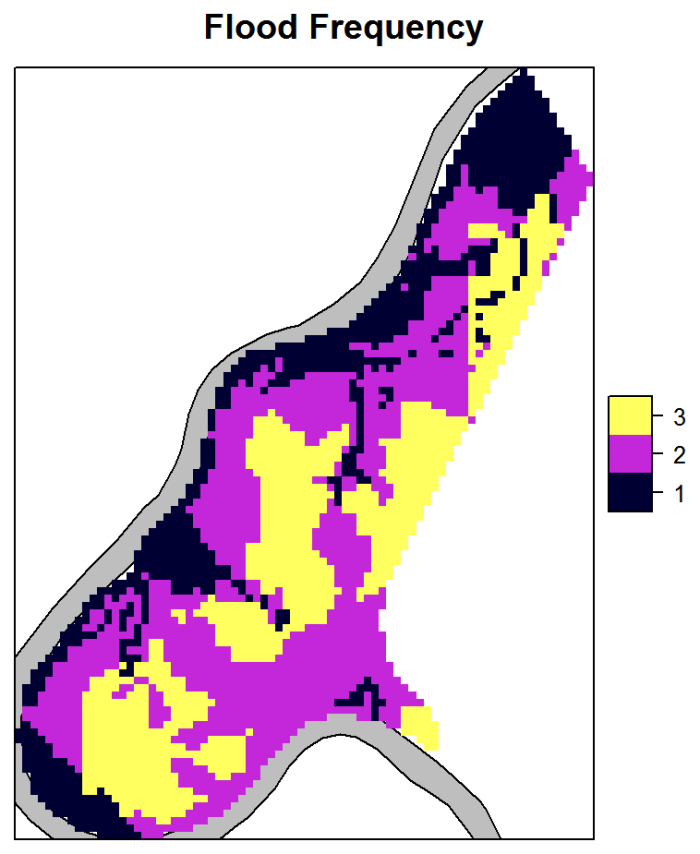
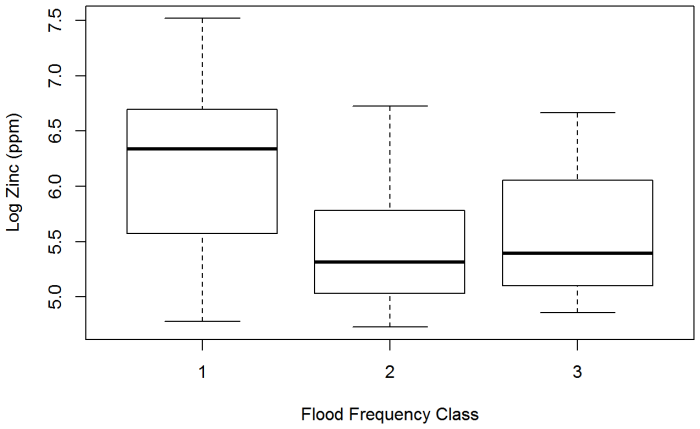
Parametric Regression – River Meuse
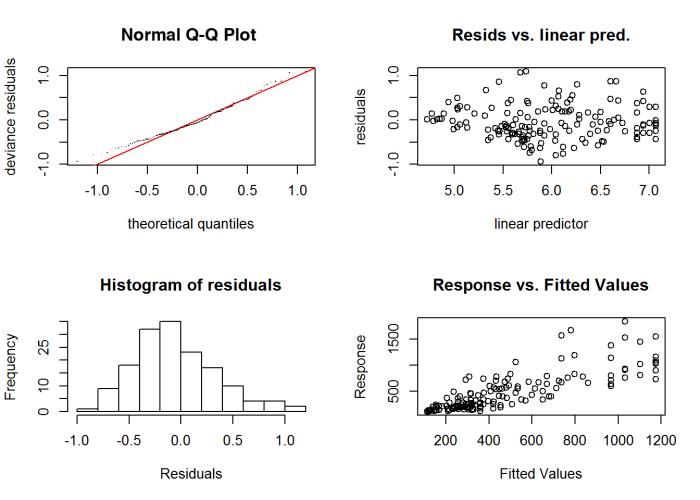 Figure 72. Diagnostic plots.
Figure 72. Diagnostic plots.Nonparametric Regression – River Meuse
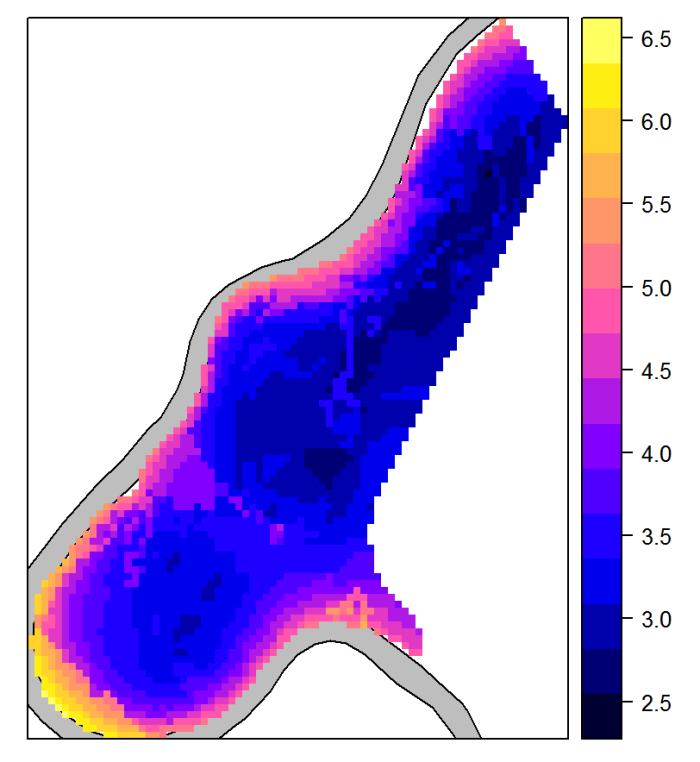
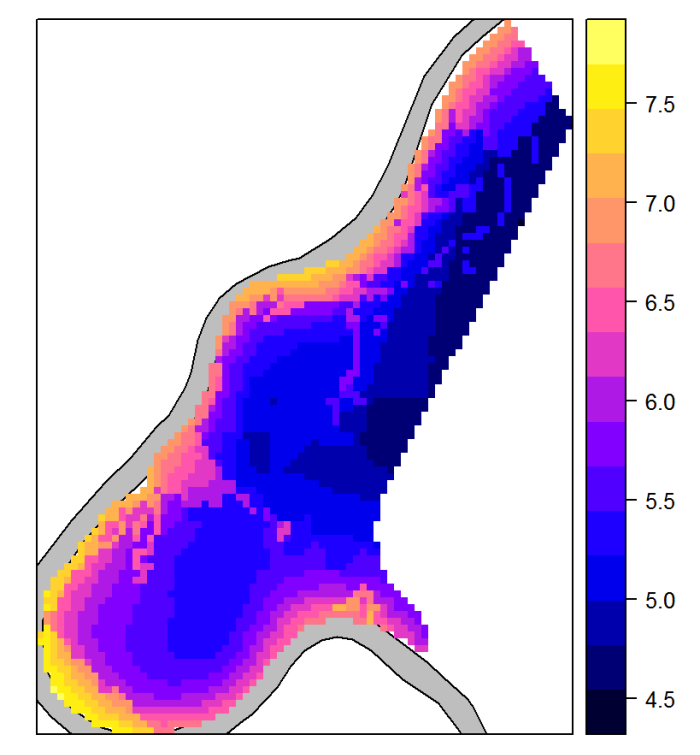 Figure 73. Predicted zinc concentrations.
Figure 73. Predicted zinc concentrations.