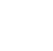Basic Data Concepts for Geospatial Analysis
Geospatial analyses assume that sample points close to one another are more related than sample points separated by a greater distance.
Spatial Dependence and Autocorrelation
Environmental properties and processes are typically related to one another in space, time, or both, making it possible to draw meaning out of environmental data. Environmental properties and processes follow Tobler’s First Law of Geography (Tobler 1970), which states: “Everything is related to everything else, but near things are more related than distant things.” This law means that sample observations that are collected close together in space or time are more related than sample observations collected farther apart. In a spatial context, the relationship between sample locations imparts meaning in a map, whether it is a geologic map or a three-dimensional visualization of a contaminant plume. Sampled data that relate to one another in space or time are called dependent data.
Sampling Geospatial Data
To perform geospatial analyses, the sampling program must adequately capture the dependence or autocorrelation of the properties being sampled. This design is difficult for complex systems, such as groundwater or soil environments. Consequently, site reconnaissance efforts or phased sampling programs can help to ensure that the right quantity and quality of data are being sampled. These data are assessed using the geospatial work flow steps. If preliminary analyses of these data indicate that the data are inadequate, geospatial analysis can be used to optimize sampling to determine additional sample locations.
Advanced Geospatial Model Assumptions
The defining feature of advanced geospatial methods is that they are based on an explicit model of spatial autocorrelation. This model must be estimated from the data. In order for this estimation to be possible, it is assumed that the statistical properties of the population from which the data are sampled do not change in space (or time). In other words, we must assume that the mean, variance, and autocorrelation do not vary in space or time (translation invariant). This assumption is called stationarity.
Advanced geospatial methods are based on the assumption that the observed data are a realization (or possible outcome) of an autocorrelated random variable. The assumption of stationarity applies to this random variable that is the basis of the advanced methods. This section describes types of stationarity as they relate to the use of advanced geospatial methods. These concepts are key for helping practitioners decide whether stationary or nonstationary advanced geospatial methods apply.
Stationarity –The assumption that the statistical properties of the population do not change over time or space. There are several types of stationarity depending on which statistical properties are assumed to be invariant over time and space. Stationarity is an important assumption for advanced geospatial methods because it allows data from different locations or times to be combined together to estimate an overall model of spatial correlation.
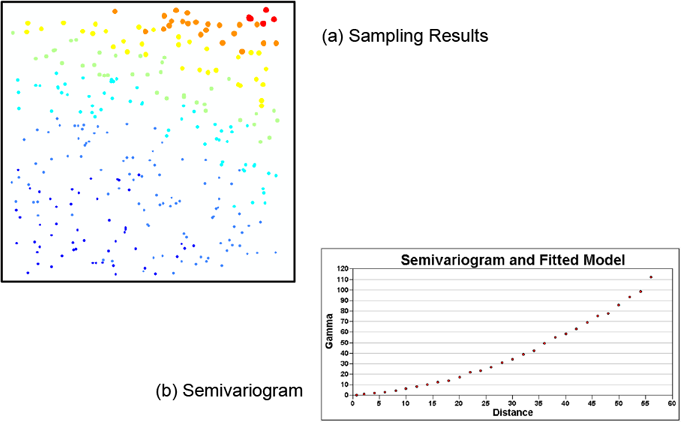
The following examples of stationarity were developed using the SAS tutorial data set. The data set has been rearranged, so the resulting data for the figures presented here are not exactly the same as the figures that would be generated directly from the SAS tutorial data set. On these figures, the concentration of a sampling point is noted by both the size of the dot and its color. The red, orange, and yellow dots have higher concentrations, with red being the highest concentrations.
Strict stationarity ▼Read more
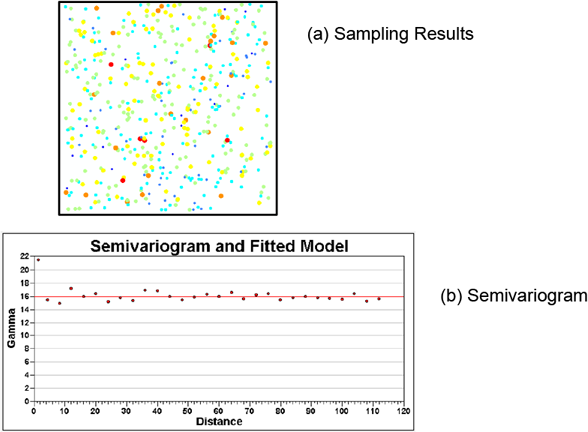
Second-order stationarity ▼Read more
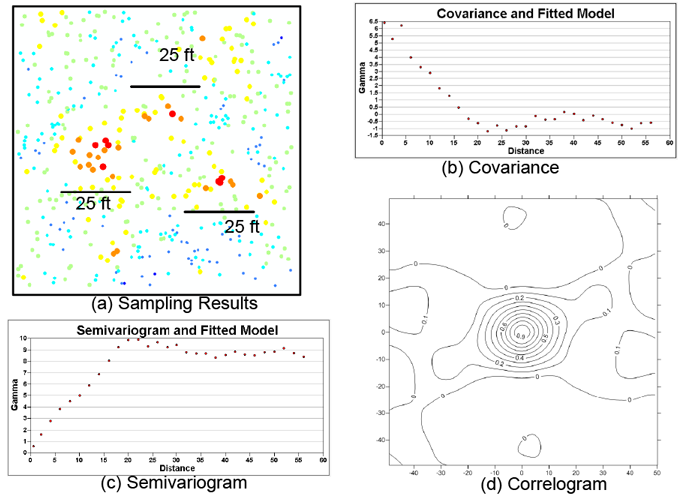
Intrinsic stationarity ▼Read more
Nonstationary data sets ▼Read more
The Work Flow section includes discussion of spatial exploratory data analysis and developing the empirical variogram for a data set. In addition, see the spatial correlation models for advanced geospatial methods section which discusses the theoretical variogram models used to describe spatial correlation.