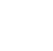Generate Geospatial Analysis Results
Once selected, the appropriate geospatial method is used to generate information for optimization. The type of results can vary depending on the study question being addressed, but the results usually include a set of predictions at unsampled locations and, for some methods, a measure of prediction uncertainty (such as standard errors or variances). If the geospatial method is being used to optimize a sampling plan, then the output of the method might be a proposed sampling plan or a metric that can be used to select new sampling locations or to remove existing sampling locations.
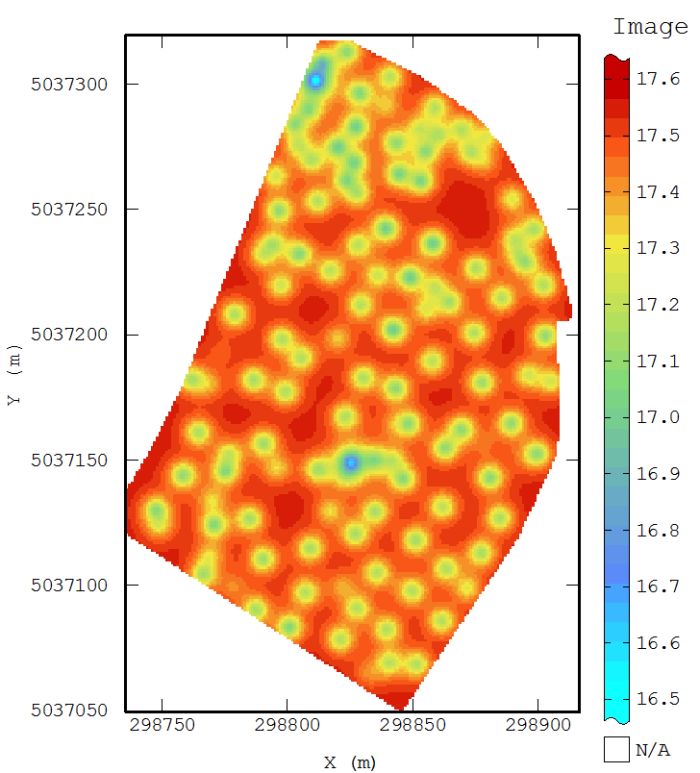
The uncertainty in the geospatial method results can be visualized by plotting the prediction variance (from regression or kriging methods) or statistical summaries of the results of conditional simulation. The most common ways of characterizing uncertainty are described in more detail in the following subsections.
Variance Map
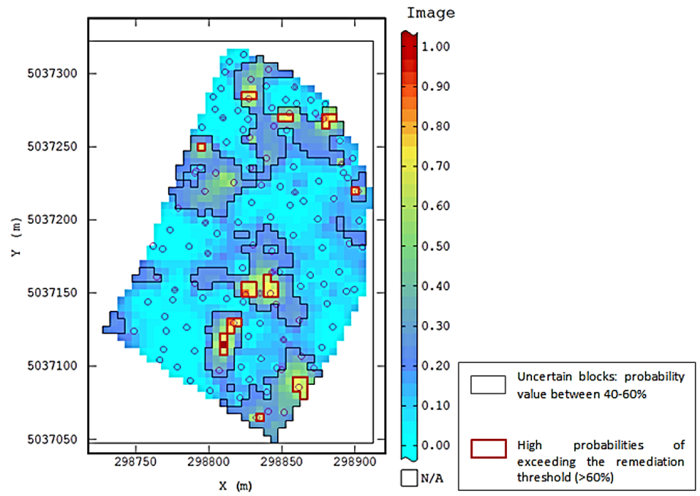
Statistical and Probability Maps
Standard Deviation Map
Probability Map