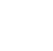Perform Exploratory Data Analysis
EDA generally refers to a collection of descriptive and graphical statistical tools used to explore and understand a data set (see GSMC-1, Section 3.3.3). EDA includes descriptive statistics such as measures of centrality (mean, median), spread (standard deviation, variance, interquartile range), and shape (skewness and kurtosis), as well as graphical displays (histograms, box plots, scatter plots, and probability plots). The initial process of data evaluation should also include GIS-based mapping to compare available concentration data with site features, topography, current and historical operations, or other available geographic information. This section presents guidance on performing EDA, including the inherent assumptions, and strengths and weaknesses of each method, and how to understand the results that are generated.
Common EDA Methods
The following standard EDA methods are typically used for an initial evaluation. Some of the methods are described in the GSMC-1 document, while others are covered in this document. The regression example includes examples of some of the plots.
- summary statistics: mean, variance, skewness, and kurtosis of the data
- scatterplots (GSMC-1, Section 5.1.3)
- histograms (GSMC-1, Section 5.1.4)
- probability plots, for example Q-Q plots (GSMC-1, Section 5.1.5)
- distributional tests to evaluate the data for normality (GSMC-1 Section 5.6)
- Pearson’s correlation coefficients (GSMC-1, Section 5.12.1)
Spatial EDA Methods
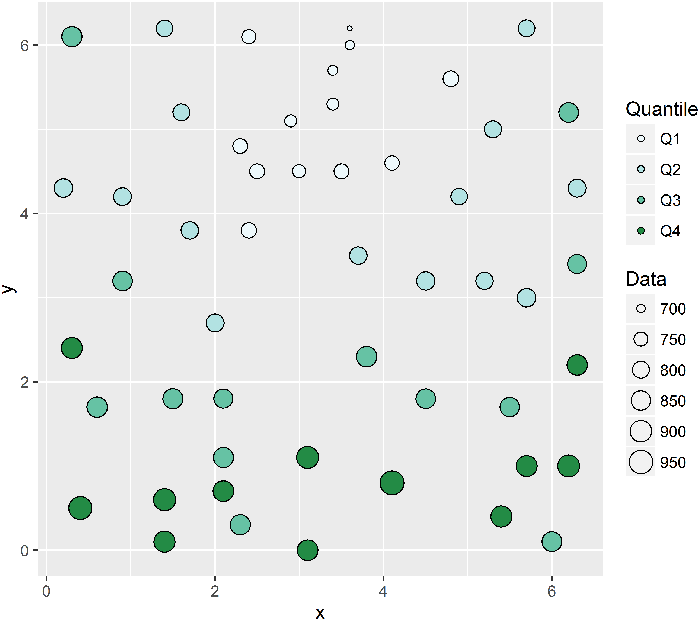
The most common EDA method for geospatial analysis is the mapping of the sample locations and posting of sampling results. The assessment of trends and outliers can be enhanced by a simple interpolation of the data in between sample points. In addition to mapping, traditional EDA methods can be modified to investigate geospatial data:
- Bin (group) the data into rows/columns (latitude and longitude) and create vertical/horizontal box plots on either side of an x-y scatter plot.
- Perform a probability plot of Z versus marginal coordinates (latitude and longitude), or probability plots of the bins.
- Generate 2D, colored scatterplots to help detect outliers.
- Analyze the scatterplot of data versus the average of m natural neighbors.
- Generate a 3D scatterplot. The scatterplot may be difficult to interpret by itself, so add a smoothed surface (such as a penalized spline) to capture general trends and look at the scatterplot as deviations from that trend.
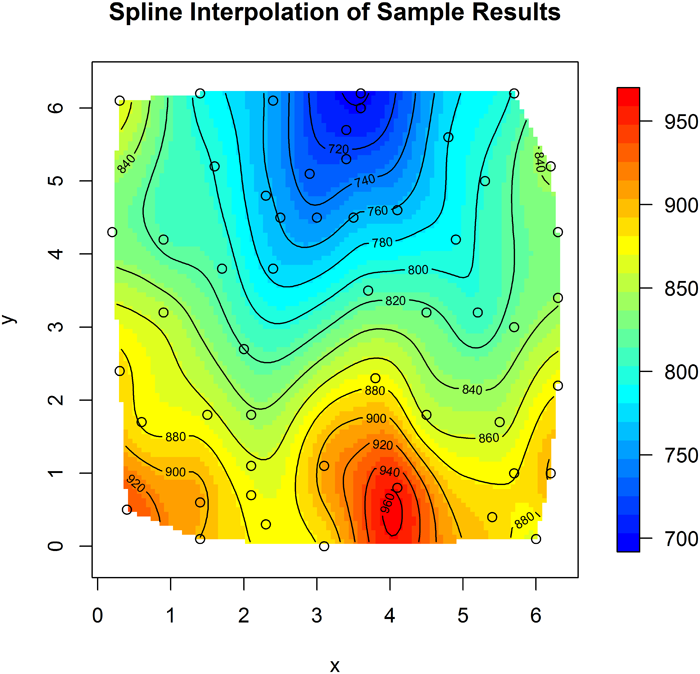
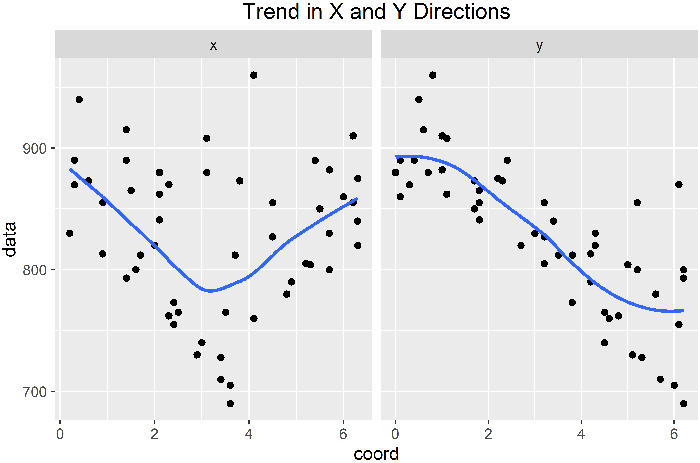
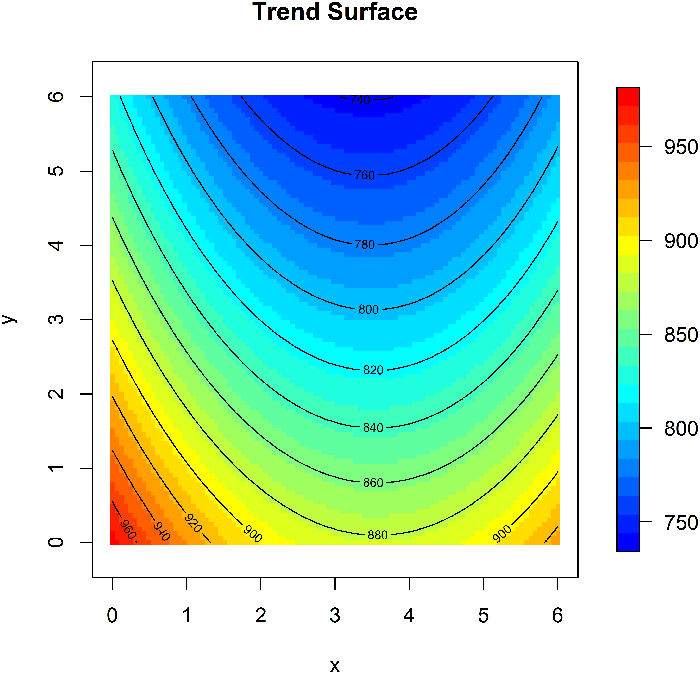
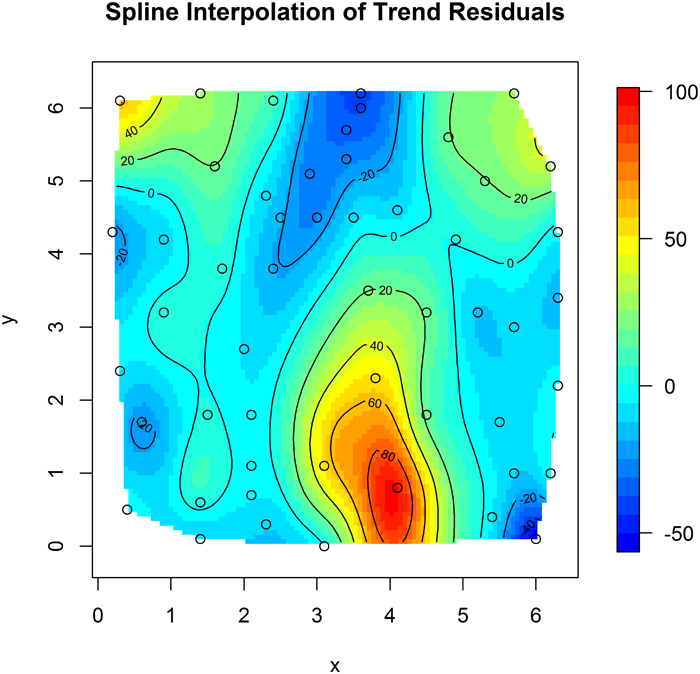
Spatial Correlation
For spatially correlated data, higher correlation is expected for points that are closer together. One of the most important objectives of EDA of geospatial data is to characterize the range of spatial autocorrelation that is exhibited in the data. This range can be used to guide sample spacing or to select an appropriate method to use for interpolation. The variogram is the most common spatial EDA method used to assess spatial correlation. Other methods that can be used include the H-scatterplot and the covariance function plot or correlogram.
Variogram
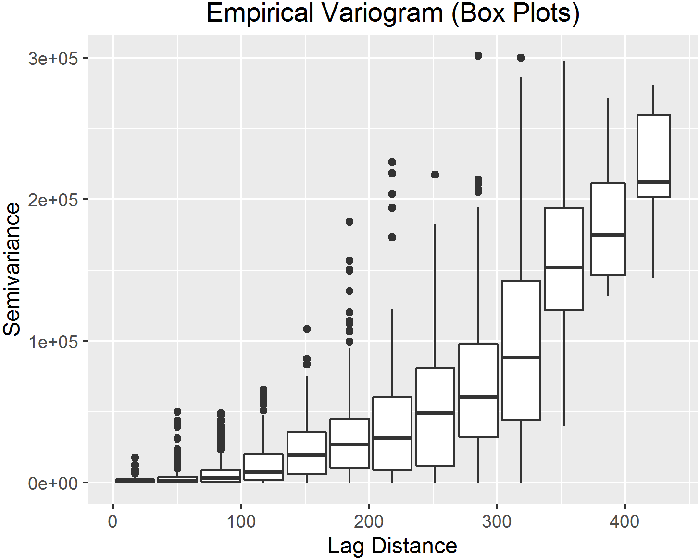
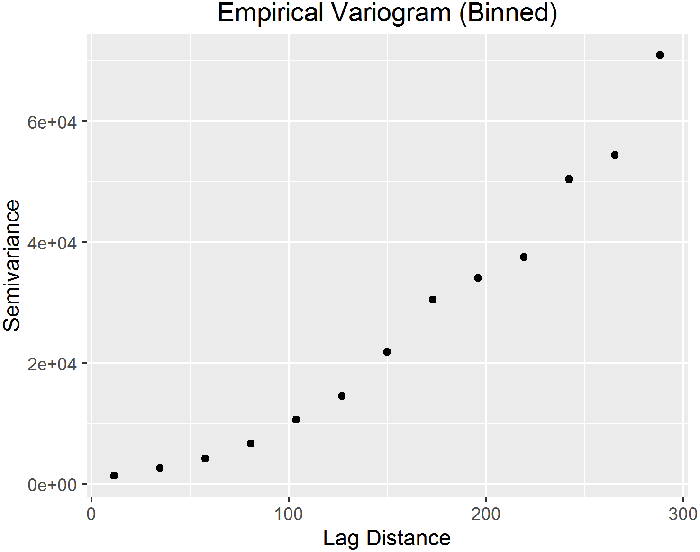
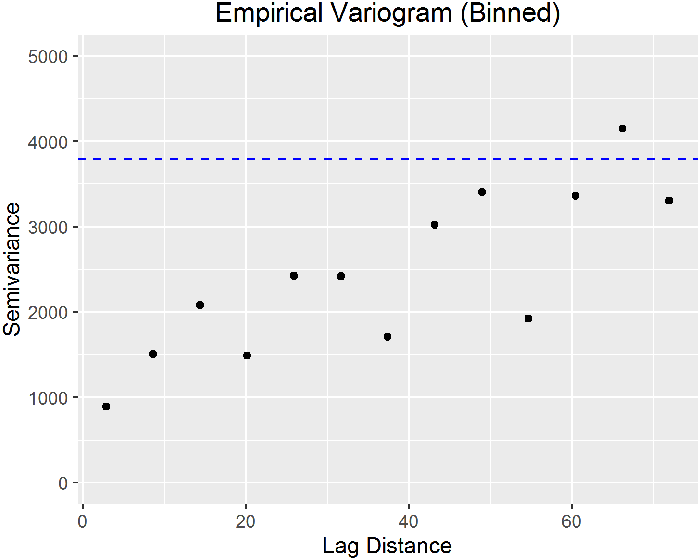
A variogram is a plot of the squared differences between measured values as a function of distance between sampling locations. The variance of the differences increases with distance until the spatial autocorrelation is no longer present (called the sill value). The lag separation distance, or lag value, where the spatial autocorrelation is no longer present is called the range. Thus, at distances less than the range measured values will exhibit spatial autocorrelation. The variogram is also referred to as a semivariogram, because the values are actually half of the variance between two points with a given lag. A plot of half of the mean of the squares of the differences in measured values grouped by lag function of distance is the empirical variogram (also called experimental variogram or sample variogram).
It is also possible to create temporal variograms to explore the temporal correlation of samples collected at a single location. The method to develop a temporal variogram is similar to a spatial variogram, with the lag distances being defined by time rather than distance. Calculating the temporal variogram for each location within a sampling area may contribute an overall understanding of how concentrations vary over time and distance.
Bins
Variogram Features
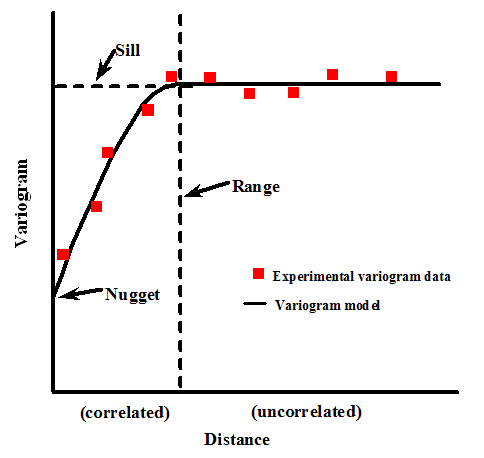
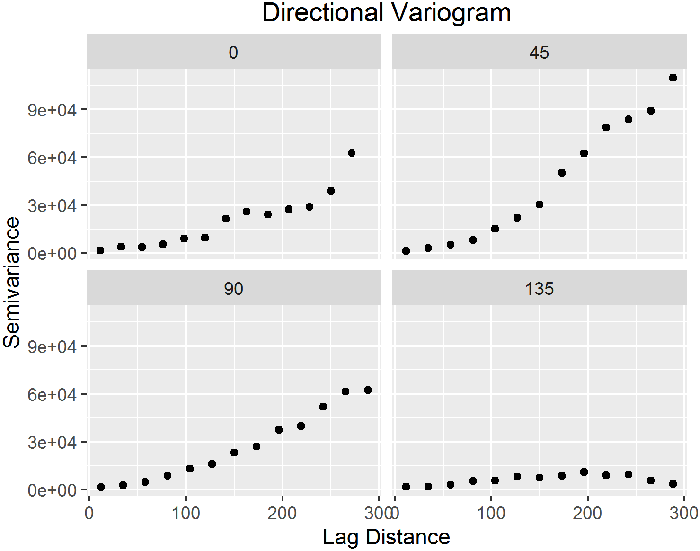
Directional Variograms and Anisotropy
Examples
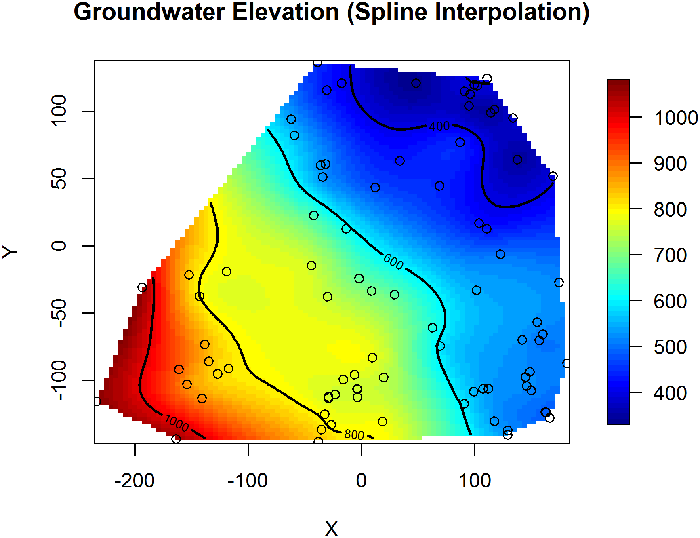
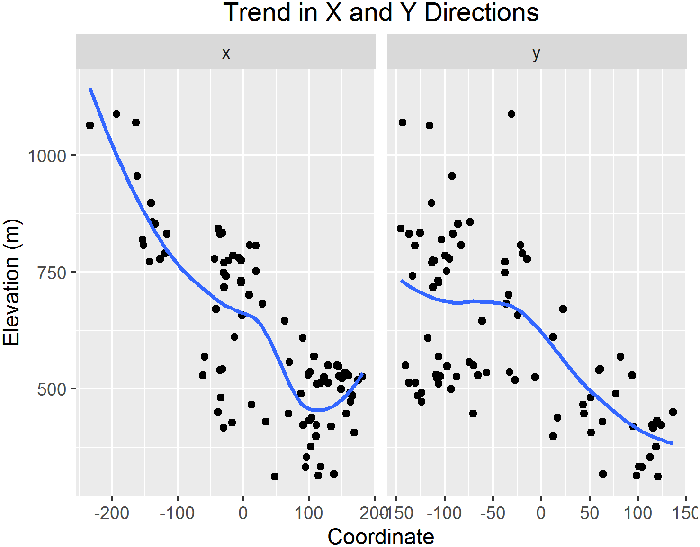
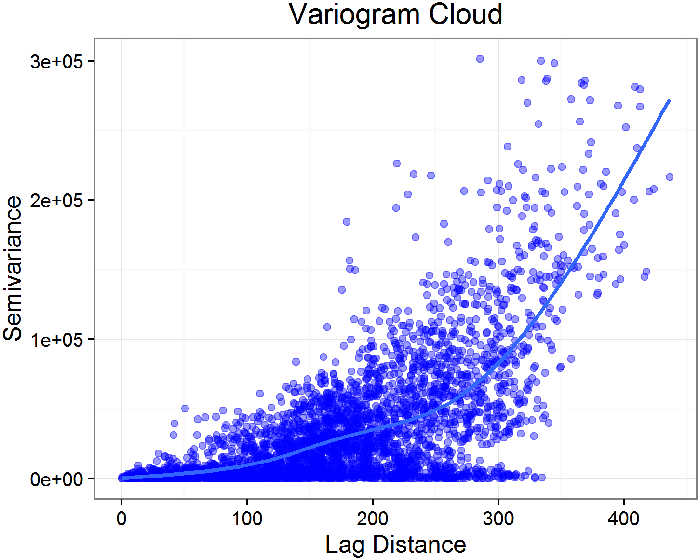
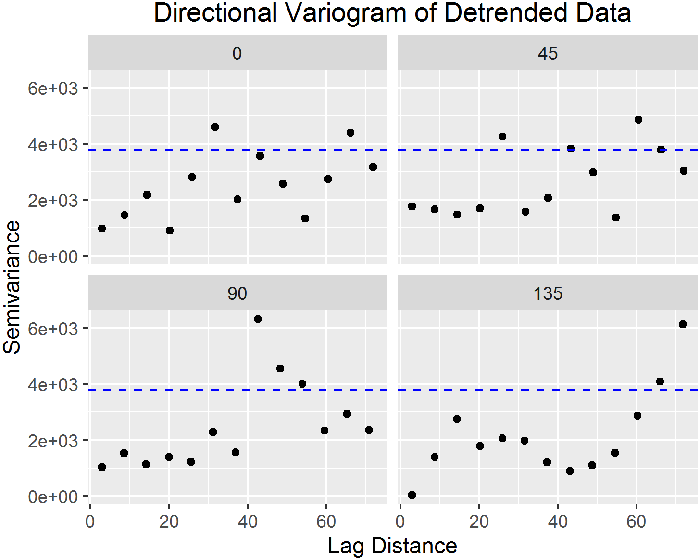
Other Methods
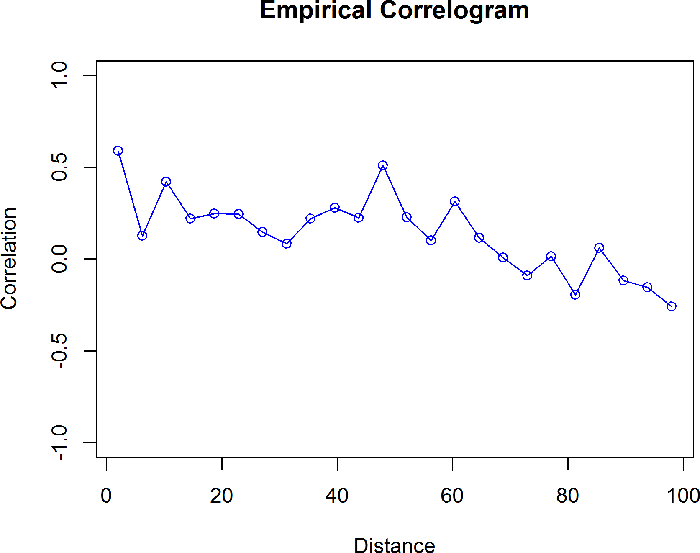
Other methods for assessing spatial correlation include H-scatterplots and plots of the covariance function or correlation.
H-scatterplots
The H-scatterplot, also called the h-scattergram or lagged scatterplot, is a tool for evaluating spatial correlation within a data set. It is a plot of the measured values for pairs of data points. For a given lag, or separation distance, measured values at each location are plotted against measurements from locations separated by that lag. The degree of scatter in the resulting plot graphically displays the degree of correlation between points with the specified lag. Examples of H-scatterplots are shown in Figures 63 and 75, in the Regression Example section.
Covariance and Correlation
Covariance and correlation are both measures of the similarity of the data values at different separation distances (lags). These measures are used to evaluate the spatial autocorrelation of the data. Correlation is a version of covariance that has been normalized so that the value is between -1 and 1.